

source file could not be read on download
Hello, I have same problem as https://support.mozilla.org/bg/questions/1026743 https://support.mozilla.org/en-US/questions/1134063
Running FIrefox 50.1.0 on Fedora 24. Cannot download file from: http://dox.bg/files/dw?a=1abb6d1a24
None of the solutions found, restarting, compreg, accept-encoding - nothing.
Read also these articles to no avail: http://kb.mozillazine.org/Source_file_could_not_be_read http://kb.mozillazine.org/Unable_to_save_or_download_files https://bugzilla.mozilla.org/show_bug.cgi?id=180672
Can anybody help? This is a serious issue IMO.
Alla svar (6)
Forgot to say that Midori can download the files just fine. Also running ff with a clean profile does not help.
The problem is only with that one site/file?
Does Firefox delete the .part file or is that still there in the directory reported by the error dialog? It's possible that you could rename that .part file to its final name as a workaround (if you get to it before Firefox removes it).
But as for what's causing it, I don't know. You already found the thread about the issue that came to mind for me.
Hm. I can't try to download that file because the CAPTCHA contains Russian characters.
Did you try a different download location and save the file to another folder? Is this a big file?
Did you check the temp folder for the permissions of this file?
You can check the Web Console (Firefox/Tools > Web Developer) for error messages about blocked and unsafe content. You can check the Network Monitor to see if content is blocked or otherwise fails to load.
You can use "Ctrl+F5" or "Ctrl+Shift+R" to reload the page and bypass the cache to generate a fresh log.
See also:
Guys, the error appears before I can choose whether to save, open or whatever the file. The window to choose appears but at the same time another error windows appears with the meaage and prevents any clicks to the download chooser window.
For me the captcha only required digits. I wonder if captcha is different depending on client source IP.
Reloading page and restarting Firefox had no effect. I tried a new clean profile to no avail. I wonder if the issue could be because of strange characters. It is not only a single file. I downloaded the files with Midori and names are like 'ì5-1_19122016(6).pdf'. I wonder if the filename characters are breaking somehow firefox. Site shows filename as "м5-1_19122016(10).pdf" so it seems like Midori remapped first char for some reason.
Looking at web console I see g analytics and some other things blocked because of tracking protection. The only interesting thing I see there is "The character encoding of a framed document was not declared. The document may appear different if viewed without the document framing it".
Probably the above could have anything to do with the issue.
Lastly the part thing. At the time error window appears, I really can copy thins `part` file. And it appears to have correct content. So issue is obviously in the code that should rename file back to the original filename. I can't understand why error happens before I have a chance to select a filename. I have configured firefox to ask me before downloading stuff but I don't have a chance to select what action do I expect.
I decided to file a new bug because all existing bugs I see are closed and may not be monitored: https://bugzilla.mozilla.org/show_bug.cgi?id=1326014
I can replicate the problem.
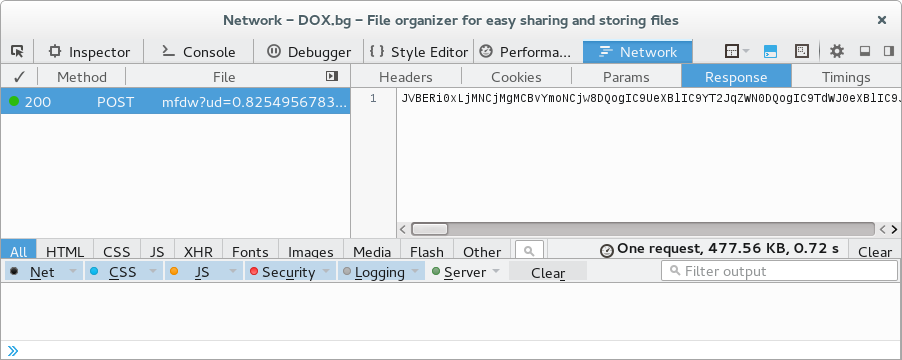
I am able to open the file in a Firefox tab by copying the base64 encoded response from the Network Monitor to the clipboard and opening this file in a Firefox tab.
- data:application/pdf;base64,JVBERi0xLjMNCjMgMCBvYmoNCjw<base64 data>CjQ4ODgxNQ0KJSVFT0YNCg==
This shows the file in the built-in PDF viewer where I can save the file.
Ändrad av cor-el