

Auto Detect setting for Text Encoding under View/Text Encoding always reverts to "off"
I receive regular emails that often (not always) fail to display the correct characters, particularly for punctuation. The bulk of the text is ok. If I turn on text encoding autodetect all is well for the email I am trying to read. But the setting always reverts to its default = off, so I have to keep going back to switch it on again. Some months ago a similar question was asked in this forum about this and a reply said the problem is usually "defective encoding on the sending side." However, there was no other useful information under that thread.
I checked the message source of a relevant email, which is a daily newsletter apparently compiled from several articles by different authors. I found nothing under 'Content-Language' but there were these entries under "charset="
Content-Type: text/plain; charset=utf-8
Content-Type: text/html; charset=utf-8 v=3D
"Content-Type" content=3D"text/html charset=3DUTF-8" />
Content-Type: text/plain; charset=utf-8
Content-Type: text/html; charset=utf-8 v=3D
"Content-Type" content=3D"text/html charset=3DUTF-8" />
Alla svar (6)
Of course it is not auto detected. It is fairly clear from what you have posted that it is explicitly stated to be UTF8, what is there to auto detect? Other than the fact the sender has made a hash of the encoding that is.
So it seems there is nothing to do but live with Thunderbird's default where autodetect = off, which after all works fine for the vast majority of emails, and every time I get one of these emails with nonsense characters scattered throughout the only remedy is to plough through Thunderbird's menus until I can set autodetect = on. This fixes the one email - hurrah! Then the autodetect setting reverts to its default, and we all go around the circle once more. Have I got this right? Is there anything I could tell the sender of the error-prone emails, who has been doing this same thing for years? I suppose "go away" would work... but I actually like the contents, usually.
Hello there jboz.
We have read your message.
We try to help you.
Sending and receiving can indeed carry viruses if, for example, the sender has sent many letters externally to another country s for example, China or Russia and may have incurred some.
This will be reflected in your text (UTF-8 )in the form of an error.
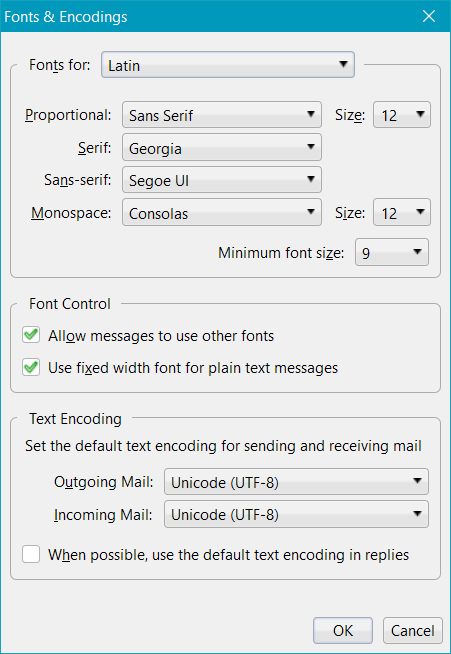
Go to the option fonts and encoding and check if the incoming and outgoing messages are filled in correctly with UTF-8 encoding language.
The code that could be the Iso file as you describe it with automatic off switch, can be changed into UTF-8 but it changed back into the Iso file.(ISO-8859-1).
ISO-8859-1 Is a good coding but can only handle a little bit if messages are continuously received as described above, it cannot afford to accumulate and so to speak.
This can be an option for a problem.
Do you guys have this option?
Greetings Firefox Volunteer.
Ändrad av День сумо
I am just curious how to set it to on. I can see the menu item, but clicking it appears to do nothing at all.
To use autodetect, open the main menu and click => view => text encoding => autodetect
This should show a menu beginning with: [tick symbol]-(off)-autodetect
Click on that line, the menu disappears and the magic happens - the misbegotten email displays correctly.
But if I go back to the menu, nothing has changed there. It still shows: [tick symbol]-(off)-autodetect
It is all very odd, which is why I ask. If the emails remained uncorrected I would assume autodetect is inert, broken, deactivated or whatever. But it works every time I have one of these mangled emails.
Hello there again. Jlboz.
THE tricky part is that you have to restart the Thunderbird software.
And there is no turn it on button for it ,it should have been placed there.
Here is how it works:
1-tools -> options -> display -> fonts (bottom, right) -> UNselect "apply the default character encoding to all incoming messages" checkbox. -> ok
2-view -> character encoding -> auto-detect -> universal
3-restart(!).
what do they mean by Universal?
Shouldn't there be UtF-8 there?
Does it work?
Do use a good antivirus.
And do not forget to update your versions of Thunderbird Software.
http://kb.mozillazine.org/Software_Update
Greetings Firefox Volunteer.
Ändrad av День сумо