

Configure text-to-speech for reading mode
Hello,
We are adding accessibility features to the Emmabuntüs Debian Edition 5 Linux distribution based on Debian 12, and we would like to use the reading mode included in Firefox to enable smoother voice reading for visually impaired people.
Currently we are going to use the Svox Pico and eSpeak speech synthesis at the same time because in SVox Pico we do not have all the voices we need for our possible users, particularly Portuguese.
We have found how to make the synthesis used by Firefox's reading mode be SVox Pico by default instead of eSpeak, however this requires a modification in the /etc/speech-dispatcher/speechd.conf file.
To do this, simply put the default pico synthesis in this file:
DefaultModule pico
But this causes problems with other software that we intend to use.
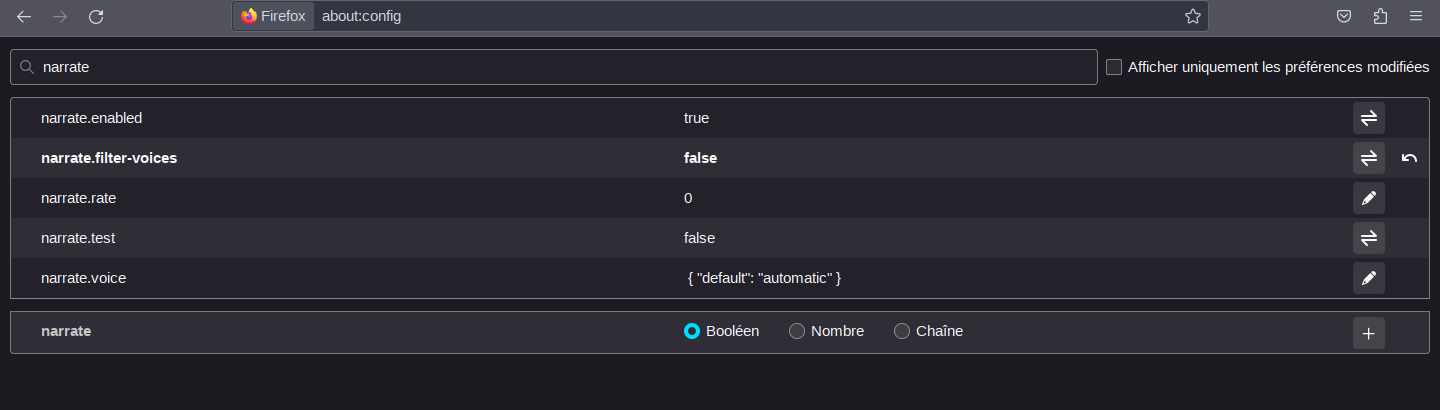
We found how to make all the voices of a speech synthesis appear in the Firefox playback menu by going to about:config and doing a search for the word "narrate":
On the other hand, we cannot find how to modify the "narrate.voice" option to tell it to default to pico speech synthesis instead of eSpeak synthesis which is the first synthesis loaded by speech-dispatcher, because we must keep eSpeak as the first synthesis loaded and do not put a default synthesis in speechd.conf to maintain compatibility with software that we wish to use.
Do you have any tips or a manual that explains the possible options for the "narrate.voice" option?
Thanks in advance for your help.
தீர்வு தேர்ந்தெடுக்கப்பட்டது
The `narrate.voice` preference is a serialized dictionary with language->voice_uri mappings. If you want to preset which voice would be used for a specific language you would do something like this: {"default" : "automatic", "en" : "__english_voice_uri__", "fr" : "__french_voice_uri__"}
To get the URI's of each voice you would open a web console on any page and type: speechSynthesis.getVoices(). Initially you might get an empty list, but do it again and it will populate with all the voice objects. The `voiceURI:` field is what you would put in the dictionary above.
You can also have more specific regional options, for example "en-US" / "en-UK".
Read this answer in context 👍 3All Replies (4)
தீர்வு தேர்ந்தெடுக்கப்பட்டது
The `narrate.voice` preference is a serialized dictionary with language->voice_uri mappings. If you want to preset which voice would be used for a specific language you would do something like this: {"default" : "automatic", "en" : "__english_voice_uri__", "fr" : "__french_voice_uri__"}
To get the URI's of each voice you would open a web console on any page and type: speechSynthesis.getVoices(). Initially you might get an empty list, but do it again and it will populate with all the voice objects. The `voiceURI:` field is what you would put in the dictionary above.
You can also have more specific regional options, for example "en-US" / "en-UK".
Thank you very much Eitan for your help and it works, but I thought I could make a selection between different voices coming from different speech synthesis, but this is not the case, only the voices of a speech synthesis are views for a configuration /etc/speech-dispatcher/speechd.conf
I wanted to do a bit like this https://ibb.co/k6nP2St It doesn't matter we will dynamically modify the /etc/speech-dispatcher/speechd.conf file according to user needs.
I may come back to the French and English Firefox forum to suggest changes to the reading mode but first we need to have an internal debate to find out how it would be well suited to visually impaired people.
That is correct, the list of synthesizers is not available through Web Speech API. It might be worth paying attention to a new speech framework which hopefully will work with Firefox soon. https://project-spiel.org/
Thank you Eitan for this information, however I don't see where the Flatpak is in question on this page https://project-spiel.org/
"Easy Distribution
Use Flatpak or Snap to give a one-click install for users. The speech provider can be fully contained and hide any complexity from host systems."
As you are a specialist in narrate mode, I would like to inform you if you wish to help us that I have just asked another question about it: https://support.mozilla.org/en-US/questions/1443538