

PDF viewer will not search
The new Firefox PDF viewer will not correctly search the text of PDF's which have text recognized. I switched the view of the document over to Acrobat and was immediately able to search as required. Can you fix?
تمام جوابات (10)
Seems to be working for me.
Does this happen with all PDF files?
The latest version of the PDF viewer is available as an extension and does a better job than the 0.6.143 version shipped with Firefox 19 in a lot of cases.
You can find the latest version of the PDF Viewer (pdfjs) extension here:
- PDF Viewer: https://addons.mozilla.org/firefox/addon/pdfjs/
Start Firefox in Safe Mode to check if one of the extensions (Firefox/Tools > Add-ons > Extensions) or if hardware acceleration is causing the problem (switch to the DEFAULT theme: Firefox/Tools > Add-ons > Appearance).
- Do NOT click the Reset button on the Safe mode start window or otherwise make changes.
It was a word-searchable document I downloaded from Lexis. I have not tested the search function further. Once I switched to Acrobat, I was able to search the document for the same terms that failed in the native extension.
I will download the updated extension. Just letting you guys know.
I can give a repeatable example. I am using FF 22 and whatever version of the PDF viewer comes with it. I don't see anything in my extensions or plug-ins that looks like a Mozilla PDF viewer. I see some "pdfjs" configuration options in about:config, so I assume that's what I'm using.
I'm looking at http://www.lrc.ky.gov/Statrev/ACTS2010RS/0055.pdf.
When I display it, click <CTRL-F>, and enter the string "section 3" (no quotes), it finds the string. However, if I search for the string "section 4", it fails to find the string. Same problem with "section 5". If I open the PDF in Adobe Reader and search for the same strings, it finds them all.
I reproduced this on two different PCs both running Windows (one Win7 and one WinXP) and FF 22.
Possibly this bug:
- bug 839096 - Searching for consecutive words is broken in pdf.js
Please DO NOT comment in bug reports: https://bugzilla.mozilla.org/page.cgi?id=etiquette.html
Thanks, cor-el
I think the bug is not related to my issue for two reasons:
- The example PDF used in describing the bug is flawed. If you open it and copy the section of text including "how files should look," then paste it into a text editor, you can see that the "fi" in "files" is a single character in some nonstandard font, not two normal characters. Naturally, neither FF nor Adobe Reader can find it. (P.S. I have run into many PDFs that have entire sections that are not in searchable text--it is a problem caused somehow in the creation of the PDF, but I haven't figured out how it happens yet.)
- In the example PDF I gave, FF does not find the target text, but Adobe Reader does, which is a different scenario.
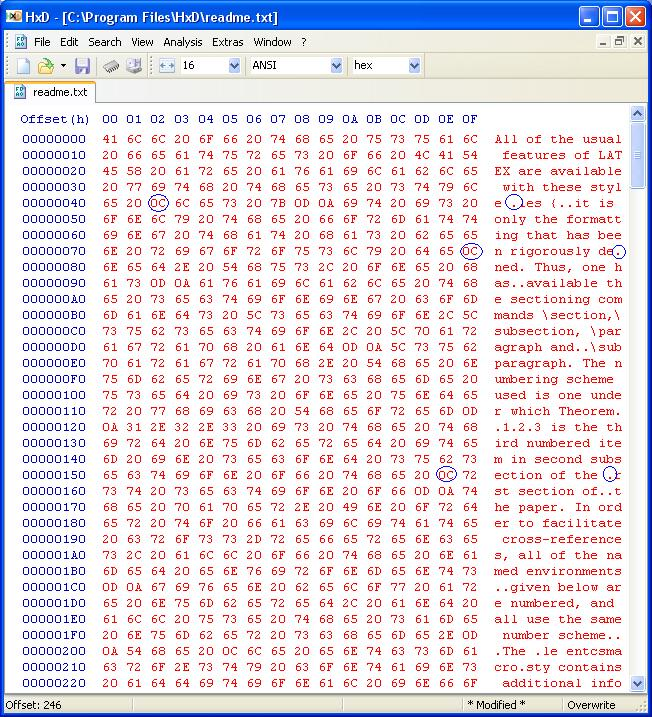
Really, I think "bug" 839096 is a red herring and probably doesn't represent a bug in FF at all. Looking at the example PDF further, most (if not all) instances of the string "fi" are nonstandard text. It has nothing to do with multiple word searches. For example, if you search for "defined," which is a single word, Adobe Reader will not find it, but it is near the top of page 4 (search for "rigorously" and you will see "defined" next to it). You might want to update the bug report with this information. I realize this thread is not about that bug, but I decided to include an image of what some of the text looks like in Notepad.
On the other hand, I have run into problems with the FF PDF viewer's search before. In the future, if I see anything, I'll pass it along.

More information: I pasted some of the text from the example PDF of bug 839096 into a hex editor and circled some of the "fi" characters in blue, which were 0Cx. Image attached.
If I select Section 4 and paste it in the Find bar (press Ctrl+F) then I get this UTF-16LE code:卥捴楯 (%u5365%u6374%u696F) (Sectio)
I can't find the 4 and if I select more text I get SectioKR (%u5365%u6374%u696F%u4B52) and this still finds both section 4 and section 5, so the find bar doesn't seem to be capable of showing the actual code
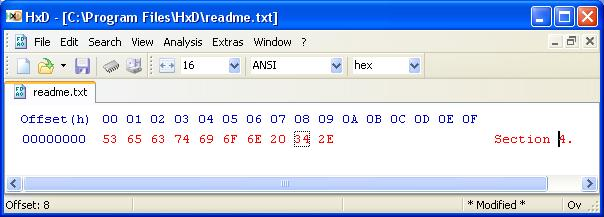
This is very interesting. I was copying from Adobe Reader, not from FF. Looking at my example, if I copy from the FF viewer, I see what you saw, which pastes into Notepad as 3 unprintable characters and into the hex editor as 000000x. However, if I open it in Adobe Reader and copy "Section 4.", it shows normal characters when I paste into the hex editor (see image).
That suggests that there is something different between the way the FF PDF viewer is interpreting the PDF and the way Adobe Reader is. Whatever Adobe Reader is doing--which could well be nonstandard--it is succeeding better than the FF viewer.
This is just 8 bit code that has been combined in 16 bit UTF-6 characters (%u5365 -> %53(S) %65(e)) that of course does not make sense as such. If you have a font that includes them then you see a (CJK) character or otherwise a square with the hex code.
I don't know if there is a bug about this that selecting text in a PDF files copies UTF-16 characters instead of the UTF-8 characters.
Well, if there is someone who could dig into the FF viewer code and the PDF contents, I expect this PDF would be a good test case. Unlike the example in the bug report, this one displays and searches perfectly in Adobe Reader.
There are a couple of other oddities. In the FF viewer, everything on page 3 from Section 4 forward shows the 16-bit characters. In that section, too, highlighting doesn't work correctly--in fact, for much of the lower part of the page, I cannot select anything. Then the page footer is okay, and page 4 is okay until Section 5, after which everything is off again.