

Firefox 39 not downloading files in one particular server
Hi. This is my first question here and a weird one too. So please bear with me.
My company has many individual servers, all running the same Java program with same environment. We have a download button to download some data. However, the download link "DOES NOT POINT DIRECTLY TO THE FILE LOCATION". Instead we take the request, process it, write the data to a file in server, then read that file to the requesting browser.
In ONE of our servers, after our firefox upgraded, we are experiencing the issue that the download is not happening anymore for versions >=39. Previous versions are able to download the file correctly. Same behavior is seen in IE-11.
What's more confusing is that other servers are behaving normally even with firefox 39 and beyond. Only with this one server I am getting this issue.
Based on FF39 changelogs, can this bug-fix have some role to play in the observed behavior ? "Fix incomplete downloads being marked as complete by detecting broken HTTP1.1 transfers"
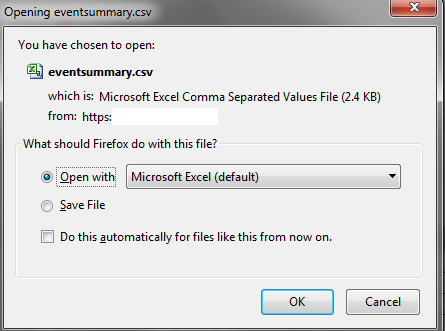
Attached are 3 images: Image 1: When download clicked, received the popup immediately though expecting some delay because of data processing. This possibly indicates that FF39 is not receiving any data from the server.
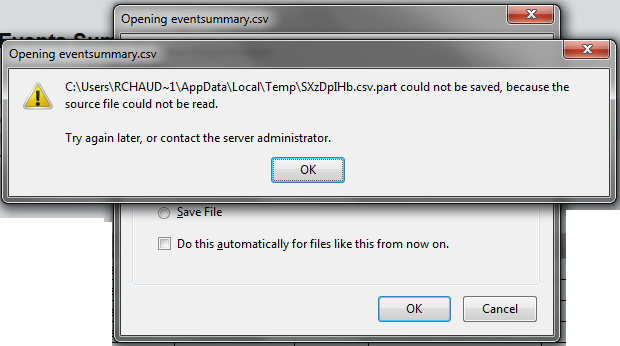
Image 2: When FF39 is not able to download the file it gives the warning shown.
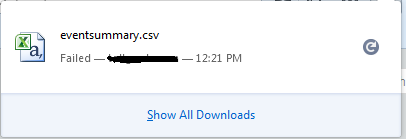
Image 3: Trying to re-download the file using download manager downloads the underlying XHTML file instead which is EXPECTED BEHAVIOR because download is not a direct link to the file as mentioned before.
PS: I understand I am not giving enough information because I don't know how to reproduce this issue. Any pointer in some direction is appreciated. Thank you for your time.
Isisombululo esikhethiwe
I found the issue:
It was because of "bad file-size". Maybe in FF39 things got stricter or something.
This was my issue: 1. Check my comment where I explained the way we calculate the file size. Our file is stored in linux system. Hence the line break is "\n". When windows machine asks for this file, we provide the data in streams and also set the size of the download file to be "TWICE THE SIZE OF ORIGINAL" to account for that extra character "\r\n" instead of just "\n". [Don't judge me. It was legacy code]. So maybe this is not the right way to calculate the file size.
2. When linux/mac machines were asking for this file, we did not had to account for additional characters. Hence everything was ok.
3. With windows machine, the file size was corrupt, hence FF was not downloading it for some reason.
We changed our code to permanently define "Line Separator" as "\r\n" because LINUX or MAC anyways ignore this "\r".
All Replies (13)
I've called the big guys to help you. Good luck.
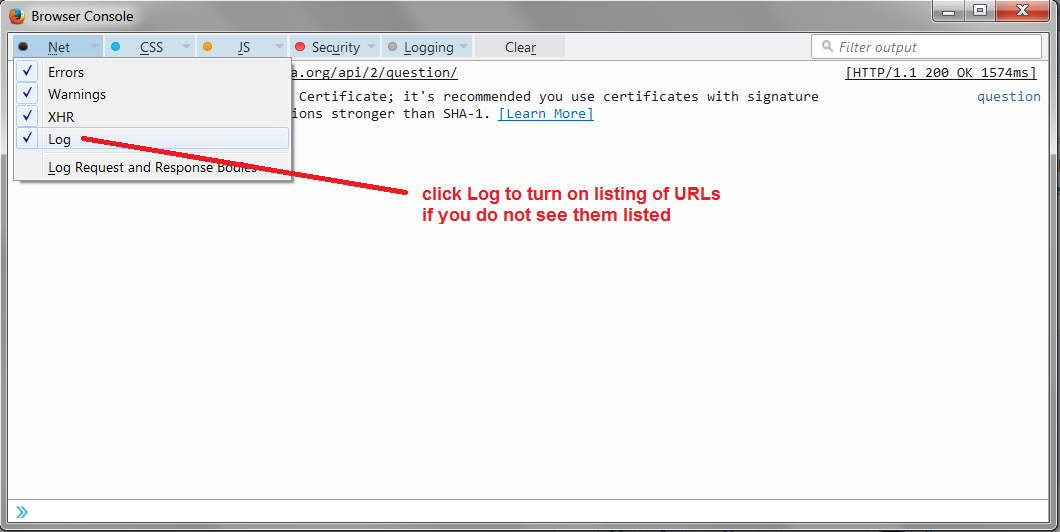
Can you find any additional information either in Firefox's Browser Console or the Web Console? The browser console is global (Ctrl+Shift+j) while the Web Console is local to a particular tab (Ctrl+Shift+k). In using either, I suggest clicking the Clear button immediately before attempting the action that is failing, to reduce clutter.
Does the download script redirect Firefox to a different host and, if so, does a direct connection to that host for the same file show anything unusual? I'm thinking in particular of SSL issues.
@jscher2000: Thanks for your reply. I did global console, cleared the console and attempted the event. The following came up.
[window] persisted focus for element "showEventSummaryForm:_t64" bridge.js:1:18811 Use of getPreventDefault() is deprecated. Use defaultPrevented instead. ace-jquery.js:14:0 [window] persisted focus for element "showEventSummaryForm:_t64" bridge.js:1:18811 [window] persisted focus for element "showEventSummaryForm:_t64" bridge.js:1:18811 TypeError: this.sink is null network-monitor.js:269:4
As I can see, only the last error is something that I think is related to this download. Everything else is just JSF/Icefaces clutter.
As for your second point, no the download does not point to another host. However, we did recently move in to SSL like a month ago. But other that shouldn't cause it, since other servers work properly.
Hmm, from Firefox's perspective, then, if there's no redirect, there's no difference in whether the download comes from back end server A or back end server B, they all appear to originate on front end server 1. How could the file store possibly be a factor? Puzzling.
Since version 33, Firefox has considered a download corrupt if the stated file size did not match the actual file size, and this could be due to measuring before rather than after compression. I'm not aware of any changes around this in Firefox 39, but it's the only remotely related thing that comes to mind.
The diagnostic for that was to disable GZIP in Firefox:
(1) In a new tab, type or paste about:config in the address bar and press Enter. Click the button promising to be careful.
(2) In the search box above the list, type or paste enco and pause while the list is filtered
(3) Double-click the network.http.accept-encoding preference and
(A) If it has the default value (line is not bolded), delete all of the text and click OK.
(B) If it has a customized value, copy the current value to a safe place for potential later use, then delete all of the text and click OK.
When you visit the site again, Firefox should omit the usual headers saying that it accepted gzip/deflate encoded responses. Any difference?
@jscher2000 Hi. I disabled the encoding part as you said, but still same results. I also tried running firefox with admin privileges thinking some perm issues. But no luck.
Regarding your first comment, in my case there are "NO" extra servers in play. All machines are independent of each other. What I meant to say was that firefox is not given a static file. The file is created on the request, and then the contents are passed to the browser like given below:
This is a legacy code. Notice the way we are calculating the file size. Its getting "multiplied by two" because windows line breaks are "4" characters "\r\n" compared to other OS ("2" characters - \r or \n).
File file = new File(filePath);
FacesContext fc = FacesContext.getCurrentInstance();
ExternalContext ec = fc.getExternalContext();
ec.responseReset();
ec.setResponseContentType("application/x-download");
Long fileLength = file.length();
ec.setResponseHeader("Content-Disposition", "attachment; filename=\"" + fileName + "\"");
output = ec.getResponseOutputStream();
printWriter = new PrintWriter(output, true);
input = new Scanner(file);
int linenumber = 0;
while(input.hasNextLine())
{
linenumber++;
String line = input.nextLine();
printWriter.write(line + lineseparator);
}
if(useragent.contains("Windows") || useragent.contains("Win")){
fileLength += ((linenumber -1) * 2);
}
ec.setResponseContentLength(fileLength.intValue());
printWriter.flush();
fc.responseComplete();
I think I was confused about the multiple servers reference in the original question. So a request to server #1 works and a request to server #2 leads to an error, and the script code is identical between the servers. Are there any differences in server configuration or in other headers being sent with the responses?
@jscher2000
There are no differences in the scripts or the configuration because we install everything via a "linux script". So all the jars, tomcat, java, etc. configuration and versions are same.
I also found that this does not happen in Firefox with Linux as host. Only when the windows is host. Did not try with MAC. So maybe the file length is the culprit here.
Okulungisiwe ngu rchaudhary
I think you can see the header with the content length in Firefox's Browser Console (Ctrl+Shift+j) even if the download ultimately fails. If you click the URL of the request, Firefox should pop up a small dialog with request and response headers. You could compare that to the actual file size downloaded in other browsers to see whether there is a mismatch. I suppose you might need to disable compression in the other browsers to do that (I don't know how).
These are the numbers.
Windows: Firefox: 2627 (Not Downloaded) Chrome: 2627 (Downloaded. Size: 2.53 KB)
Linux: Firefox: 2555 (Downloaded. Size: 2.5KB)
Its downloading in Windows Chrome and Linux Firefox. So I guess that the file length is correct. Something else is wrong.
Are we going in the right direction?
Did you compare the file to see where they differ?
Are this binary files or text files?
In case of the latter there might be a line endings change where Linux geta a LF (0x0a) and Windows a CR/LF (0x0d 0x0a)
@cor-el The downloaded files are normal text/csv files. I have not checked the binary of these files, but I am sure that windows gets a "\r\n" and linux only gets a "\r". The reason why I am sure is because the variable `lineseparator` in my above code decides what sort of line break to put based on the requesting host. So if windows asked for a file, the `lineseparator` will be "\r\n".
I don't have anything else at the moment. Here are the threads with that error explanation, which go all over the place but might contain something worth exploring: https://support.mozilla.org/search/advanced?a=1&q=%22Source+file+could+not+be+read%22&sortby=1&w=2
Isisombululo Esikhethiwe
I found the issue:
It was because of "bad file-size". Maybe in FF39 things got stricter or something.
This was my issue: 1. Check my comment where I explained the way we calculate the file size. Our file is stored in linux system. Hence the line break is "\n". When windows machine asks for this file, we provide the data in streams and also set the size of the download file to be "TWICE THE SIZE OF ORIGINAL" to account for that extra character "\r\n" instead of just "\n". [Don't judge me. It was legacy code]. So maybe this is not the right way to calculate the file size.
2. When linux/mac machines were asking for this file, we did not had to account for additional characters. Hence everything was ok.
3. With windows machine, the file size was corrupt, hence FF was not downloading it for some reason.
We changed our code to permanently define "Line Separator" as "\r\n" because LINUX or MAC anyways ignore this "\r".